Overview
The goal of this presentation is to introduce the audience to an agentic SDK—specifically the Google Agent Development Kit (ADK), while addressing a critical trap in modern AI engineering. It is incredibly easy to fall into the habit of building AI agents using basic procedural code or siloed Jupyter Notebooks. While these approaches work for initial validation, they fail to scale in an enterprise environment.
Instead, this session demonstrates how to leverage robust software design patterns and foundational architectural principles. By building an abstraction layer over the SDK, we can create a mature, enterprise-ready library. This approach allows us to decouple our core business logic from third-party frameworks, making our codebase completely agnostic to any single SDK and giving us the flexibility to swap underlying tools as the AI ecosystem evolves.
Follow the next sections for the main points of the presentation, and then take a look at the video presentation to dive deeper into the concepts.

Presentation Summary
Discover how to transition from building monolithic, single-prompt chatbots to designing highly modular, scalable, and extendable enterprise agents using the Google Agent Development Kit (ADK). This presentation provides a hands-on architectural deep dive into building process-oriented workflows, implementing the Model Context Protocol (MCP) for cloud data platform integrations, and utilizing automated DevOps tooling to eliminate technical debt in your AI engineering pipelines.
The Monolithic Prompt & SDK Trap
When developers start building AI agents, the initial momentum is almost always driven by quick prototyping. You pull down a hot new SDK, run a quick pip install, and start hardcoding prompts directly into your files.
While this works for a weekend hobby project, it quickly collapses under its own weight in an enterprise ecosystem. You end up with multiple developers writing siloed, inconsistent code, duplicating core tasks like error handling, and introducing massive technical debt. Even worse, your entire system becomes tightly coupled to a single third-party framework. If you ever need to pivot or replace that framework, you are looking at a complete rewrite.
Production-grade engineering requires moving away from spaghetti code toward process-oriented, SDK-agnostic architecture.
Architectural Blueprint: Layered Agent Design
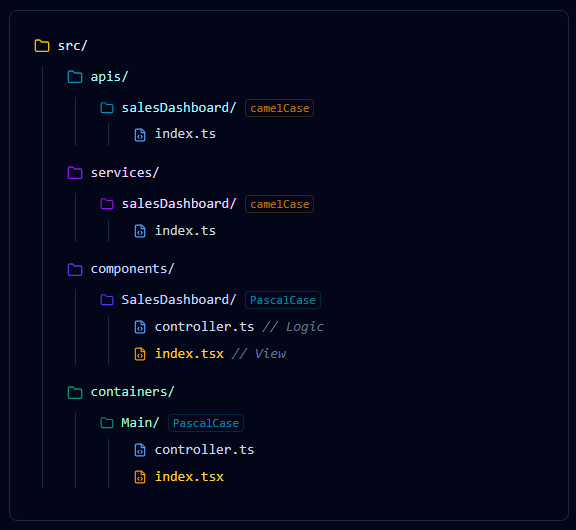
To achieve true reusability and governance, we must build a core architectural foundation that abstracts third-party dependencies away. Instead of letting an external SDK dictate our application structure, we stack agents in specialized layers via inheritance.

1. The Base Agent (The Foundation)
The BaseAgent is an abstract base class responsible for handling cross-cutting concerns that every enterprise agent needs:
- Consistent logging structures.
- Centralized security and exception handling.
- Standardized interface definitions.
By encapsulating these inside a base layer, any new agent you spin up automatically inherits these core enterprise features.
2. The Basic Agent (Configuration over Hardcoding)
The BasicAgent extends the base layer to introduce configuration management. To keep our code robust and maintainable, prompts should never be hardcoded.
Instead, the BasicAgent pulls details—like the target Gemini model or project IDs—from environment variables. Simple instruction hooks can be fed via configurations, allowing your DevOps pipeline to deploy behavior updates or model rollouts without requiring a single line of code to change.
3. The Tool Agent (Advanced Governance & MCP)
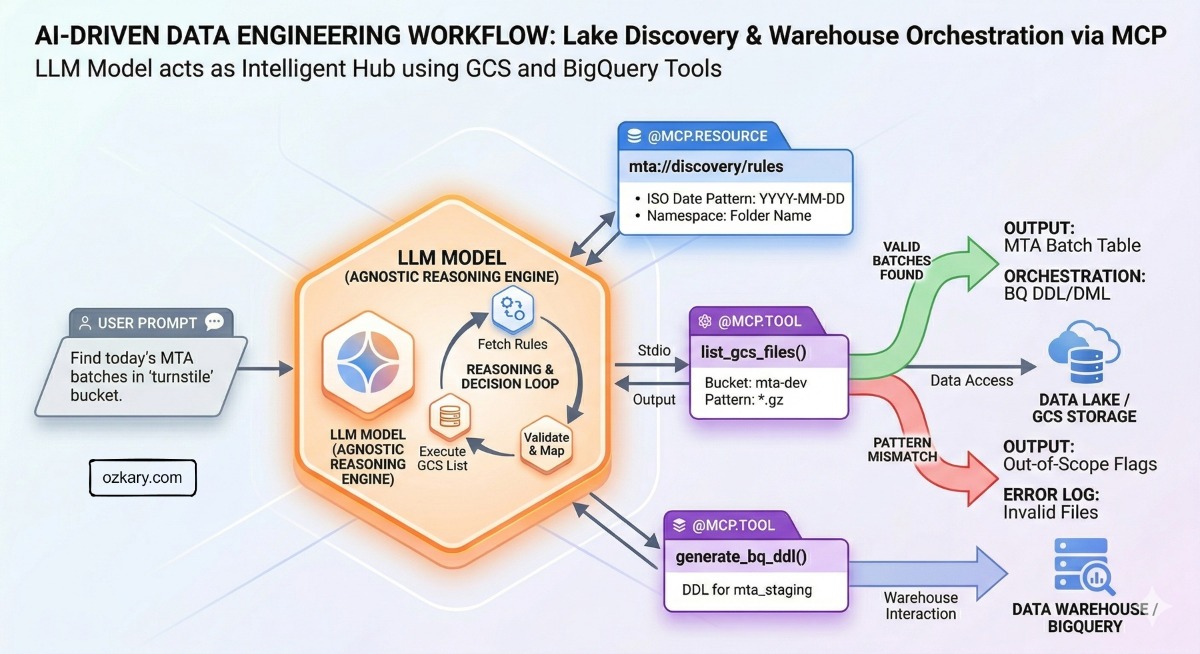
The ToolAgent introduces external capabilities through the Model Context Protocol (MCP). For complex enterprise needs, configuration files aren’t enough. The ToolAgent uses file pointers to read advanced Markdown documents detailing strict system instructions, safety limitations, data boundaries, and governance rules.
Extending Capability with Custom & Native MCP Tools
An agent on its own is just an engine that knows how to talk to a Large Language Model. To make it useful, it needs a way to interact with the outside world. This presentation highlighted two separate paradigms for handling tools:
Abstracting Built-in SDK Tools
The Google ADK provides out-of-the-box tools for major platforms like BigQuery. However, to maintain code isolation, we shouldn’t map those tools blindly. In the demo code, we extended the native tool using a custom authorization class (AuthorizationContext). This separation of concerns ensures that token generation, credential refreshing, and cloud authentication happen entirely independent of the agent’s reasoning loop.
Building Custom MCP Tools from Scratch
When an SDK lacks a tool for your specific business requirements—such as interacting with a custom file bucket or specific database—you can build your own using frameworks like FastMCP. The presentation demonstrated a custom Google Cloud Storage (GCS) tool capable of:
- Listing target bucket contents.
- Generating compressed file previews.
- Executing self-diagnostic checks to validate connections before a workflow begins.
The Unsung Hero: The Agent Runner Runtime
One of the least understood components of agentic design is the Agent Runner. While the Google ADK provides an excellent local web-based playground that automatically bootstraps your environment for rapid testing, production environments require you to explicitly script this runtime pipeline.
The Agent Runner acts as the orchestrator of your system, managing three vital elements:
- Orchestration: Connecting multi-agent workflows (e.g., passing tasks seamlessly between a storage agent and a BigQuery data agent).
- Session Management: Directing the active state of an execution path.
- Memory Management: Maintaining persistence. While short-term tasks can run on fast, volatile in-memory sessions, complex industrial or manufacturing pipelines require long-term history to monitor trends, catch system drift, and diagnose process failures over time. The presentation demonstrated wiring an isolated SQLite engine into the runner to handle this tracking cleanly.
Modern DevOps for AI: UV and Makefiles
Enterprise code demands automated quality gates. Rather than relying on standard global package structures, the project repository leverages modern Python tooling to accelerate developer onboarding:
UV (Virtual Environment Manager): A lightning-fast, modern alternative to legacy virtualenv tools. Using a strict uv.lock file ensures every developer on your team runs identical dependency versions, entirely eradicating the “it works on my machine” problem.
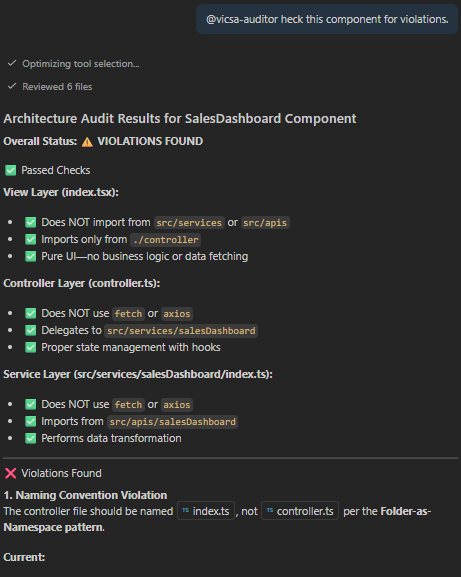
Makefiles as CI/CD Blueprints: Instead of manually typing tedious execution commands, a standard Makefile orchestrates development tasks. Running make lint catches configuration errors and unmapped dependencies (like an imported but unused session config) before the code ever reaches a code review, while commands like make run-tool smoothly handle localized testing.
Key Takeaways for Enterprise Developers
- Isolate the SDK: Treat third-party agent frameworks as pluggable libraries, not foundational pillars. Abstract them behind abstract base classes so you can swap architectures with minimal friction.
- Configuration Wins Over Code: Keep your agent identities, target models, and governance logic inside Markdown and environment variables. Let your DevOps pipelines drive system behavior.
- Rely on Runtimes for Memory: Keep your agents lean. Let specialized agent runners handle the operational state, session history, and database logging.
Resources & Next Steps
Get the Code: Explore the foundational structures, base classes, and custom MCP tool definitions by visiting the official GitHub Repository. (Don’t forget to star the repo if you find the patterns helpful!)
Dive Deeper into Engineering Processes: For a comprehensive guide on building scalable, process-oriented architectural systems, check out my book, “Data Engineering Process Fundamentals”.
🤖 Artificial Intelligence
Focus: LLM Patterns and Agentic Workflows

🚀 Featured Open Source Projects
Explore these curated resources to level up your engineering skills. If you find them helpful, a ⭐️ is much appreciated!
🏗️ Data Engineering
Focus: Real-world ETL & MTA Turnstile Data


📉 Machine Learning
Focus: MLOps and Productionizing Models

💡 Contribute: Found a bug or have a suggestion? Open an issue! and be part of the open source project.
YouTube Video
Take a look at this video and learn about building and testing agents using the Google Agent Development Kit (ADK) by leveraging its CLI and web tool. We’ll start from the absolute basics, learning how to build a simple agent and test it instantly.
From there, we will move on to extend our agents by building custom Model Context Protocol (MCP) tools. Throughout this session, we will focus on staying away from hardcoded prompts. Instead, you’ll learn how to leverage clean software design patterns to build truly reusable, extendable agents that can adapt dynamically with the use of configurable prompts and plug-and-play MCP tools, shifting your development loop from a one-off script or simple notebook into a scalable, production library.
👍 Subscribe to the channel to get notify on new events!
🌟 Let’s Connect & Build Together
Thanks for reading! 😊 If you enjoyed these resources, let’s stay in touch! I share deep-dives into AI/ML patterns and host community events here:
- GDG Broward: Join our local dev community for meetups and workshops.
- Global AI Events: Join Global AI Events.
- LinkedIn: Let’s connect professionally! I share insights on engineering.
- GitHub: Follow my open-source journey and star the repos you find useful.
- YouTube: Watch step-by-step tutorials on the projects listed above.
- BlueSky / X / Twitter: Daily tech updates and quick engineering tips.
👉 Originally published at ozkary.com